不可描述的 iOS 锁事
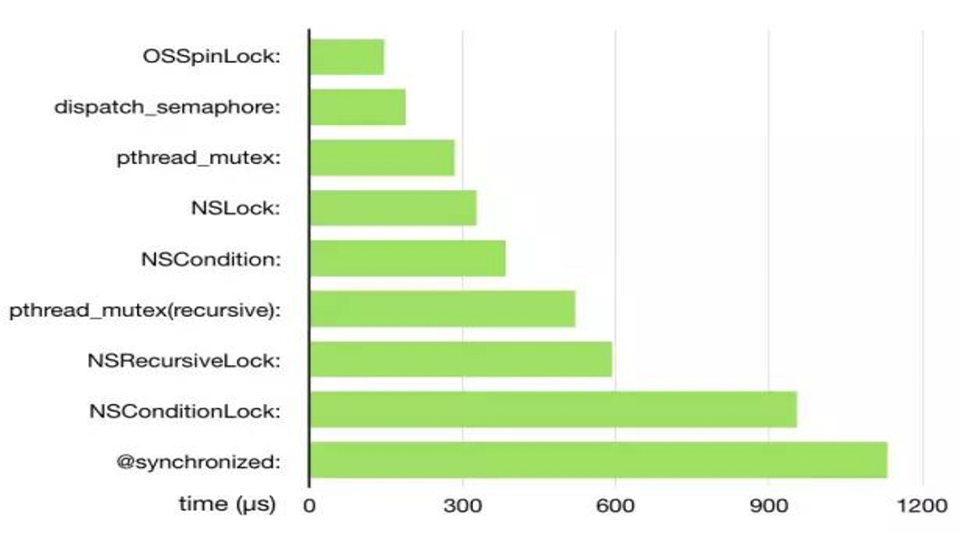
- 常用锁性能比较:
互斥锁(Mutex): 是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。它的原子性确保了如果一个线程锁定了一个互斥量,将没有其他线程在同一时间可以锁定这个互斥量。它的唯一性确保了只有它解锁了这个互斥量,其他线程才可以对其进行锁定。当一个线程锁定一个资源的时候,其他对该资源进行访问的线程将会被挂起,直到该线程解锁了互斥量,其他线程才会被唤醒,进一步才能锁定该资源进行操作。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步锁: 是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。也就是说使用信号量可以使多个线程有序访问某个资源。
自旋锁: 自旋锁,和互斥锁类似,都是为了保证线程安全的锁。自旋锁当一个线程获得锁之后,其他线程将会一直循环在那里尝试执行,查看是否该锁被释放。CPU被浪费,执行速度快。所以,此锁比较适用于锁的持有者保存时间较短的情况下。
递归锁: 可以被一个线程多次获得,而不会引起死锁。它记录了成功获得锁的次数,每一次成功的获得锁,必须有一个配套的释放锁和其对应,这样才不会引起死锁。只有当所有的锁被释放之后,其他线程才可以获得锁。
显示锁: 较
synchronized内置在代码里面的隐式锁。显示锁需要我们获取锁,释放锁。锁对象越小越好
@synchronized 关键字加锁
MrPeak杂货铺里面有篇很好的文章:正确使用多线程同步锁@synchronized()
当我在源码全局搜索synchronized的时候,很容易就找到了(当然也在Xcode中选择菜单Product->Perform Action->Assemble "xxx.m“,看到_objc_sync_enter、_objc_sync_exit这2个函数):
1 | // Begin synchronizing on 'obj'. |
感兴趣的可以下载源码看看
分析
synchronized中传入的object的内存地址,被用作key,通过hash map对应的一个系统维护的递归锁mutex来做同步。
所以:
- 不管是传入什么类型的object,只要是有内存地址,就能启动同步代码块的效果。
synchronized内部采用递归锁mutex(底层应该还是使用的pthread_mutex_t),我们可以嵌套使用,不会造成死锁:1
2
3
4
5
6@synchronized (obj) {
NSLog(@"1st sync");
@synchronized (obj) {
NSLog(@"2nd sync");
}
}我们可以使用
pthread_mutex_t递归锁来代替synchronized:
例如:1
2
3
4
5
6
7+(id)fooFerBar:(id)bar {
@synchronized(self) {
static NSDictionary *foo = nil;
if (!foo) foo = [NSDictionary dictionaryWithObjects:...];
}
return [foo objectWithKey:bar];
}
上面的例子,用pthread_mutex_t来代替,虽然很难看,但是性能好很多
1 | #include <pthread.h> |
@synchronized(nil)不起任何作用
从源码我们可以看到synchronized传入对象为空时,什么都没有做
注意
MrPeak大神也指出了几点注意的地方:
使用
@synchronized(self)带来的死锁精准的粒度控制
synchronized 是互斥锁,是同类中最方便的隐式锁,性能虽然较差,但是我们也应该把握粒度。
从源码我们可以知道,@synchronized(obj) 中的 obj 通过 hash 算法存储到了一份手动维护的 cache 中,cache 的 key 使用的是 obj 的内存地址。hash 算法恰能以 O(1)的时间复杂度,以 obj 为 key 取出对应的锁。即内容与位置之间的快速映射关系,也即是一个地址对应一个锁;@synchronized 使用多了之后,快速的通过 obj 取出对应的锁,能够达到优化多线程的性能的作用。
🔞 错误做法
1 | @synchronized (sharedToken) { |
❗️❗️❗️ 任何时间都只有一个线程在临界区内执行。
我们可以这么理解:一栋大楼,里面有很多小房间,每个房间里面装是不同”代码”。现在我们只想一次让一个人进去房间,办法就是在外面”加锁”。”锁”的范围可以加在房间上,也可以加在整栋楼的大门上。而现在这种情况就好比是加在整栋楼的大门上,一旦进去有人进入A房间,即使有人想要进去B房间也会被”锁”在整栋的大门外(阻塞)。(整栋楼就是临界区)。所以最好的办法就是进行粒度控制,锁加载每个”房间门”的外面。获取锁的对象”范围越大”,临界区”越广”。
所以如果是在不同的线程,另一个线程会造成阻塞。
✅ 正确做法
1 | @synchronized (tokenA) { |
- 注意内部的函数调用
{}内部有其他隐蔽的函数调用。比如:
1 | @synchronized (tokenA) { |
doSomethingWithA内部可能又调用了其他函数,维护doSomethingWithA的工程师可能并没有意识到自己是被锁同步的,由此层层叠叠可能引入更多的函数调用,代码就莫名其妙的越来越慢了,感觉锁的性能差,其实是我们没用好。
NSLock.h 里面的4中锁
在【高性能iOS应用开发】书中提到:锁是进入临界区的基础构件。atomic属性和@synchronized块是为了实现边界实用的高级别抽象。
在NSLock.h里面一共存在4把锁,都遵守NSLocking协议,分别是获取锁,释放锁。
1 | @protocol NSLocking |
NSLock 对象锁
NSLock 是一种低级别的锁。一旦获取了锁,执行则进入临界区,且不会允许超过一个线程并行执行。释放锁则标记这临界区的结束。
1 | // _cpuUsageLock是一个私有字段,也可以是一个属性 |
NSLock 必须在锁定的线程中进行解锁。
在调用lock之前,NSLock必须先调用unlock。所以如果连续锁定两次,已经获取了锁,再去获取锁,线程会因为等待锁的释放而进入睡眠状态,因此就不可能再释放锁,则会造成死锁问题。如果想要达到递归锁的效果,可以使用NSRecursiveLock。
NSRecursiveLock 递归锁
NSRecursiveLock允许在被解锁前锁定多次。如果解锁的次数与锁定的次数相匹配,则认为锁释放,其他线程可以获取锁。当类中有多个方法使用同一个锁进行同步,且其中一个方法调用另一个方法时,NSRecursiveLock非常好用。
1 | - (instancetype)init |
每个锁定操作都有一个相应的解锁操作与之匹配。
NSCondition
NSCondition 可以协调线程之间的执行。一个线程会等待释放锁的变量条件,另一个线程会通知条件变量释放锁,并唤醒等待中的线程。NSCondition 可以原子性地释放锁,从而使得其他等待的线程可以获取锁,而初始的线程继续等待。
- 举个典型的例子:
消费者取得锁,取产品,如果没有,则线程会wait,这时会释放锁,直到有线程唤醒它去消费产品;
生产者制造产品,首先也是要取得锁,然后生产,再发signal,这样可唤醒wait的消费者,最后释放锁。 broadcast和signal的区别:
消费者和生产者都有可能会等待,所以broadcast是唤醒所有线程,而signal 只会通知一个等待的线程- 值得注意的是:
lock和unlock是成对出现的。 - RAC里面也有一个很好理解的示例:
RACCommand被执行execute的时候底层调用了- (id)first,最终执行代码如下:
1 | - (id)firstOrDefault:(id)defaultValue success:(BOOL *)success error:(NSError **)error { |
NSConditionLock 条件锁
NSCondition 和 NSConditionLock很像,同样的生产者消费者模型,我们可以使用 NSConditionLock 。当生产者执行执行的时候,消费者可以通过特定的条件获得锁,当生产者完成执行的时候,它将解锁该锁,然后把锁的条件设置成唤醒消费者线程的条件。
关于NSConditionLock这篇文章讲的很好
1 | // 用于condition等于特定值的时候获取锁,会阻塞当前线程。 |
pthread_mutex 互斥锁(C语言)
pthread 表示 POSIX thread,定义了一组跨平台的线程相关的 API,pthread_mutex表示互斥锁。
1 | /* |
NSLock内部封装了一个 pthread_mutex,属性为 PTHREAD_MUTEX_ERRORCHECK。所以会存在跟NSLock一样的死锁问题。想要在临界区内再获取锁,做好将属性设置为PTHREAD_MUTEX_RECURSIVE
dispatch_semaphore 信号量实现加锁(GCD)
信号量实现的显示锁
dispatch_semaphore 是 GCD 用来同步的一种方式,与他相关的共有三个函数,分别是
- dispatch_semaphore_create:定义信号量
- dispatch_semaphore_signal:使信号量+1
- dispatch_semaphore_wait:使信号量-1
当信号量为 0 时,就会做等待处理,这时其他线程如果访问的话就会让其等待。所以如果信号量在最开始的的时候被设置为1,那么就可以实现“锁”的功能:
执行某段代码之前,执行dispatch_semaphore_wait 函数,让信号量减 1 变为 0,执行这段代码。
此时如果其他线程过来访问这段代码,就要让其等待。
当这段代码在当前线程结束以后,执行 dispatch_semaphore_signal 函数,令信号量再次 加1,那么如果有正在等待的线程就可以访问了。
需要注意的是:如果有多个线程等待,那么后来信号量恢复以后访问的顺序就是线程遇到 dispatch_semaphore_wait 的顺序。
这也就是信号量和互斥锁的一个区别:互斥量用于线程的互斥,信号线用于线程的同步。
从首页的图可以看出,自旋锁和信号量加解锁耗时分别排行一二。深入理解 iOS 开发中的锁的作者强调指出:加解锁耗时不能准确反应出锁的效率(比如时间片切换就无法发生),它只能从一定程度上衡量锁的实现复杂程度。
- SDImageCache 中的例子
1 | // 内存缓存 weakCache -- NSMapTable |
OSSpinLock
关于OSSpinLock自旋锁,可以看大神YY的博客不再安全的OSSpinLock
按照YY大神的描述:
操作系统在管理普通线程时,采用的是时间片轮转算法。每个线程会被分配一段时间片(quantum),通常在 10-100 毫秒左右。当线程用完属于自己的时间片以后,就会被操作系统挂起,放入等待队列中,直到下一次被分配时间片。这样的算法会存在潜在的优先级反转问题。
当低优先级的线程获得锁并访问共享资源,这时一个高优先级的线程也尝试获得这个锁,它会处于 spin lock 的忙等状态从而占用大量 CPU(占着cpu,却获取不到锁)。此时低优先级线程无法与高优先级线程争夺 CPU 时间,从而导致任务迟迟完不成、无法释放 lock。
除非开发者能保证访问锁的线程全部都处于同一优先级。
当一个进程正处在某临界区内,任何试图进入其临界区的进程都必须进入代码连续循环,陷入忙等状态。
os_unfair_lock
在 iOS 10/macOS 10.12 发布时,苹果提供了新的 os_unfair_lock 作为 OSSpinLock 的替代,并且将 OSSpinLock 标记为了 Deprecated。
1 | os_unfair_lock_t unfairLock; |
pthread_rwlock
从名字就可以看出跟读写相关的锁–读写锁
- 当读写锁被一个线程以读模式占用的时候,写操作的其他线程会被阻塞,读操作的其他线程还可以继续进行。
- 当读写锁被一个线程以写模式占用的时候,写操作的其他线程会被阻塞,读操作的其他线程也被阻塞。
1 | // 初始化锁 |
总结
- 高性能的时候就用
dispatch_semaphore或pthread_mutex。iOS10以上可以用os_unfair_lock。 - 想简单方便就用
@synchronized。